

2021.09.17 현대자동차그룹
컴퓨터가 반복적인 학습을 통해 정답에 가까운 답을 도출해내는 것, 우리는 그것을 딥러닝(Deep Learning)이라고 부릅니다. 이미 사진 속 얼굴인식, 온라인 쇼핑몰의 유사제품 검색, 음성인식, 챗봇 등으로 생활 속에 깊숙이 자리 잡은 기술입니다. 컴퓨터가 학습한 결과를 바탕으로 정답을 도출하기 때문에 정제된 데이터를 활용한 반복적인 학습이 딥러닝 알고리즘을 더욱 정교하게 만들 수 있습니다. 따라서 딥러닝 알고리즘을 활용할 때에는 많은 데이터를 확보하여 정확한 정보를 반복적으로 학습시키는 것이 중요합니다.

자료를 입력시키면 스스로 학습하는 딥러닝, 말은 쉽지만 과정은 그렇지 않은 경우가 많습니다. 어떤 물체를 인식시킬 것인지를 일일이 라벨링 작업 후에 학습시키는데, 라벨링 작업에 들어가는 시간과 노력이 만만치 않기 때문입니다. 게다가 인식할 물체가 추가된다면 어떻게 될까요? 새로 추가된 물체에 대해 라벨링 과정을 다시 거쳐야 합니다. 만약 예측 성능이 만족스럽지 못하면 추가 데이터에 대해 라벨링 과정을 거쳐야 됩니다. 이러한 과정을 무한히 반복해 딥러닝의 성능을 향상시켜야 합니다.
딥러닝의 학습 데이터를 만들기 위해서는 라벨링 단계가 반드시 필요합니다. 그런데 라벨링에 소요되는 자원이 너무 크다면 업무 적용 시 효율이 떨어지겠죠? 그래서 어떻게 하면 라벨링 작업시간을 줄일 수 있을까 연구를 했습니다.
실제로 저희는 부품 촬영을 통해 부품의 위치와 형상을 판단하는 프로젝트를 진행했습니다. 딥러닝을 통해 실제 이미지에서 부품의 위치와 형상을 예측하는 프로젝트입니다. 말씀드린 것처럼 딥러닝을 학습시키기 위해서는 라벨링 작업이 필요합니다. 백지상태의 컴퓨터에게 사진 속 어떤 부품을 인식하라고 알려주기 위해 학습 데이터를 만드는 작업입니다. 사람은 감각을 통해 대략적인 예상을 할 수 있지만, 컴퓨터는 학습한 데이터를 바탕으로 대조하여 판단합니다.

부품의 위치를 예측하기 위해서는 촬영된 부품 사진을 사각형으로 라벨링을 하고, 부품의 형상을 예측하기 위해서는 부품을 다각형으로 정교하게 라벨링 해야 합니다. 최소 1천장의 학습 데이터가 필요한데, 예측을 해야 할 부품이 56개나 존재하기 때문에 학습 데이터를 만드는 것만 해도 물리적인 시간이 많이 소요되는 부분입니다.
다행히도 차량을 설계할 때는 모든 부품을 3D 모델로 제작합니다. 따라서 부품에 대한 상세 정보를 이미 가지고 있는 것이죠. 이를 잘 활용하면, 일일이 사람의 힘으로 라벨링을 하는 것보다 더욱 정교하고, 빠르게 딥러닝을 학습시킬 수 있을 것이라 생각했습니다. 예측해야 할 부품의 3D 모델을 다양한 각도와 스케일로 캡처를 하고, 이를 딥러닝의 학습 데이터로 활용하여, 최종적으로 딥러닝이 실제 사진에서 부품의 위치와 형상을 찾아낼 수 있도록 하고자 했습니다.
딥러닝이 판단을 할 때에는 정비 현장의 실제 사진으로 판단을 해야 하므로, 학습 데이터 또한 실제 사진과 유사해야 합니다. 사람의 눈으로는 3D 렌더링 이미지와 실제 사진의 유사점을 쉽게 판단할 수 있지만, 컴퓨터는 그렇지 못하기 때문입니다. 따라서 3D 렌더링 이미지의 캡처본을 실제 사진처럼 변환하는 단계가 필요했고, 이를 위해서 GAN 알고리즘을 활용했습니다.
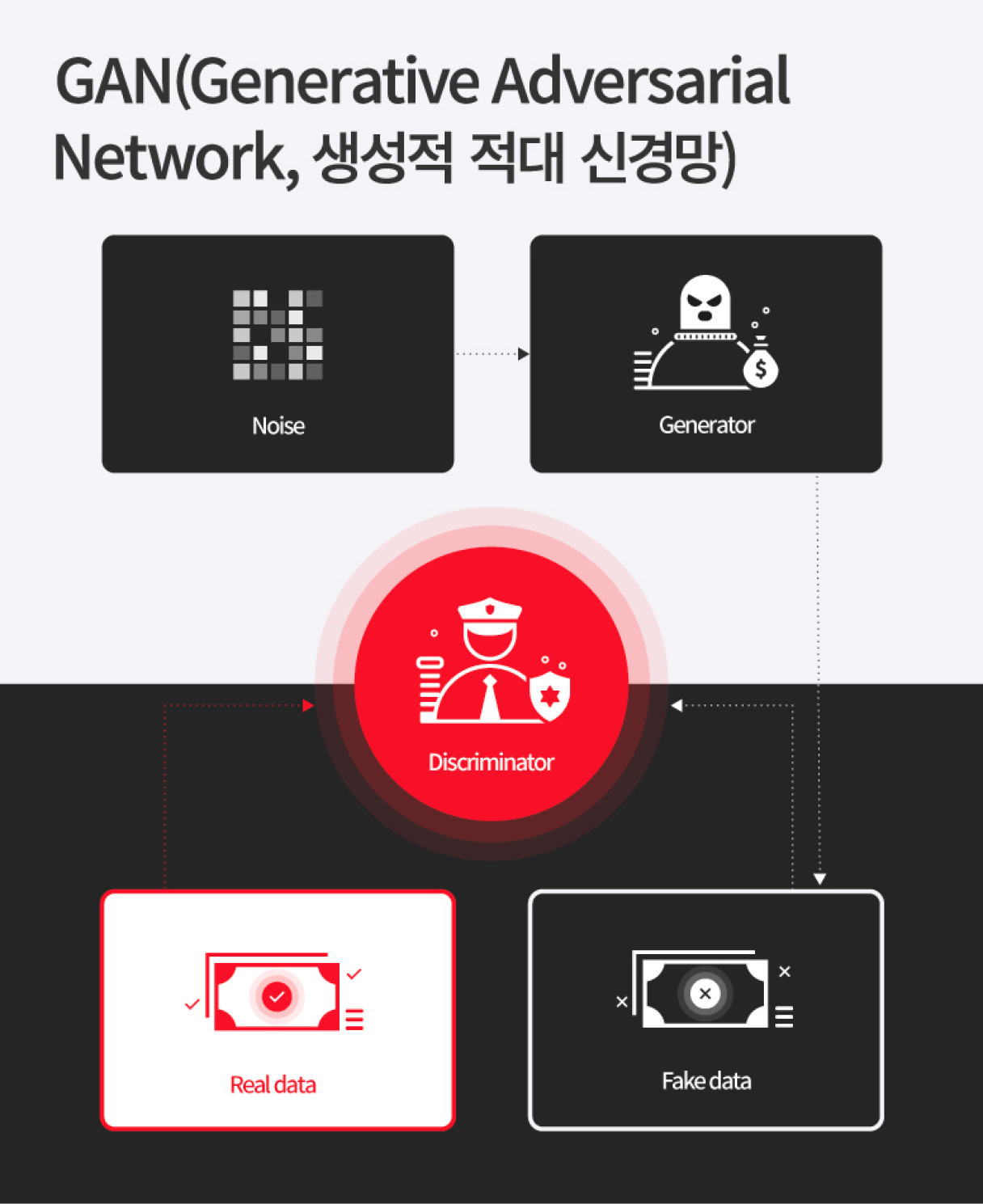
GAN은 주로 위조지폐범과 경찰관에 빗대어 설명합니다. 위조지폐범은 최대한 정교하게 위조지폐를 만들고, 경찰관은 이를 판단합니다. 위조에 실패할 때마다 위조지폐범이 점점 더 정교하게 위조지폐를 만듦으로써 실제에 더 가까워지는 방식입니다. GAN을 통해 3D 모델을 실제 사진에 최대한 가깝게 변환할 수 있고, 이를 학습 데이터로 활용합니다. 이를 통해 딥러닝은 정제된 데이터를 통한 학습이 가능해지고, 결과적으로 예측 정확도도 높아집니다.

GAN을 통해 최대한 실사에 가까운 데이터를 생산하고, 해당 데이터로 위치를 예측하는 딥러닝을 학습시킵니다. 3D 파일을 통해 부품의 위치를 자동으로 사각형으로 라벨링 할 수 있기 때문에, 기존에 사람의 손으로 일일이 라벨링을 하던 단계는 더 이상 필요하지 않습니다. 그리고 실제 3D 모델을 바탕으로 더 다양한 각도에서의 촬영이 가능하므로 학습 데이터도 무한으로 만들어낼 수 있습니다. 더 정교한 데이터, 그리고 더 많은 데이터의 학습을 진행한다는 것은 AI의 판단을 더욱 정확하게 할 수 있다는 것을 의미합니다.
실사에 가까운 학습 데이터로 위치를 예측하는 딥러닝 학습이 완료되었으니 이제 판단 단계로 넘어가 보겠습니다. 정비 사진을 통해 부품의 형상을 찾아내는 것이 목표이지만, 해당 사진의 위치를 먼저 예측하고, 그 위치에 해당하는 부품의 형상을 예측함으로써 판단의 정확도를 높일 수 있습니다. 위치 예측을 과정에는 널리 쓰이고 있는 Faster RCNN 알고리즘을 사용했으며, 실제 촬영 이미지를 입력했을 때 부품 위치를 잘 예측하는 것을 확인했습니다.

위치를 예측했으니 이제 부품의 형상을 예측합니다. 3D 모델의 외곽선과 사진 속 부품의 외곽선이 일치하면 해당 부품으로 인식하고, 형상을 예측할 수 있을 것입니다. 사람의 눈으로는 어디가 외곽선인지 쉽게 구분이 가능하겠지만, 컴퓨터는 그렇지 않습니다. 따라서 외곽선만 부각할 수 있도록 조치를 취해야 합니다.

외곽선을 부각시키기 위해 SLIC 알고리즘을 사용했습니다. SLIC 알고리즘은 이미지에 균등하게 정의된 점들을 뿌리고, 주변의 비슷한 데이터를 묶어 영역을 나눕니다. SLIC 알고리즘을 점의 개수를 변경해가며 경계를 구하고, 해당 경계들의 평균을 구하면 부품의 외곽선만 부각되는 등고선 같은 depth map을 만들 수 있습니다. 그리고 3D 모델의 외곽선과 depth map을 비교하여 최소한의 오차를 가질 때까지 3D 부품의 X, Y, Z 각도와 Scale에 변화를 줍니다. 이를 통해 부품의 형상을 찾을 수 있습니다.

기존의 방식대로 딥러닝을 통해 부품의 형상을 인식시키기 위해서는 라벨링 작업이 필요하고, 이로 인해 단순 작업시간을 많이 필요로 했습니다. 따라서 라벨링 단계를 자동으로 할 수 있는 방법을 고안해 냈고, 그렇게 만들어진 3D 모델을 활용한 자동 라벨링 개발 스토리는 아래와 같이 요약할 수 있을 것 같습니다.
1. 실제 사진을 라벨링 하여 학습 데이터를 만드는 것은 시간 소모가 크다.
→ 기존 3D 모델 렌더링 이미지를 활용해 라벨링을 자동화하자.
2. 딥러닝의 학습 데이터로 활용하려면 실사와 유사한 데이터여야 한다.
→ GAN 방식으로 3D 렌더링 이미지를 실사처럼 꾸미자.
3. 부품을 판단하기 위해 위치와 형상을 예측해야 한다.
→ 위치는 Faster RCNN, 형상은 3D 부품과 부품의 외곽선 매칭으로 예측하자.
4. 부품 형상 찾기 완료!
딥러닝으로 해결 가능하지만 학습 데이터가 부족한 경우 위에서 소개 드린 3D 자동 라벨링 기술을 활용해 학습 데이터를 증가시키고, 라벨링에 소모되는 시간을 크게 줄일 수 있습니다. 현대차그룹에서는 이미 다양한 분야에 딥러닝을 활용하고 있지만, 추가적으로 딥러닝이 필요한 경우 좀 더 쉽고 빠르게 딥러닝을 적용할 수 있을 것으로 기대됩니다.

현대자동차그룹 위민국 매니저
이미지 분석 업무를 하고 있습니다.
그리고 이미지 분석을 보다 쉽고 편리하게 할 방법을 모색하는 중입니다.