


안녕하세요? 현대자동차그룹 전동화음향진동리서치랩 노경진 책임연구원입니다.
2016년 구글 딥마인드의 알파고와 바둑 기사 이세돌 9단의 대국은 전 세계의 이목을 집중시켰습니다. 이후 AI(Artificial Intelligence, 인공지능)는 모든 산업에 스며들었습니다. 기술은 거듭해서 고도화되고 있으며, 인프라 역시 거대해지고 있습니다.
현대자동차그룹은 ‘스마트 모빌리티 프로바이더’를 지향하며 AI 기반의 개발 문화를 형성하고, 모빌리티에 AI를 활용한 다양한 서비스를 제공하기 위해 노력하고 있습니다. 이러한 시대적 흐름에 맞춰 전동화음향진동리서치랩은 소음과 진동, 신호처리 및 AI 기반 상태(고장) 진단 프로젝트 경험을 통해 쌓은 노하우를 바탕으로 누구나 쉽고 빠르게 AI 진단 모델을 생성할 수 있는 A²DS(Auto-AI Diagnostic Solution)를 개발했습니다. 지금부터 A²DS는 어떤 기능적 특징이 있는지, 어떻게 개발되었는지 등을 알아보고 향후 계획까지 소개해드리려고 합니다.
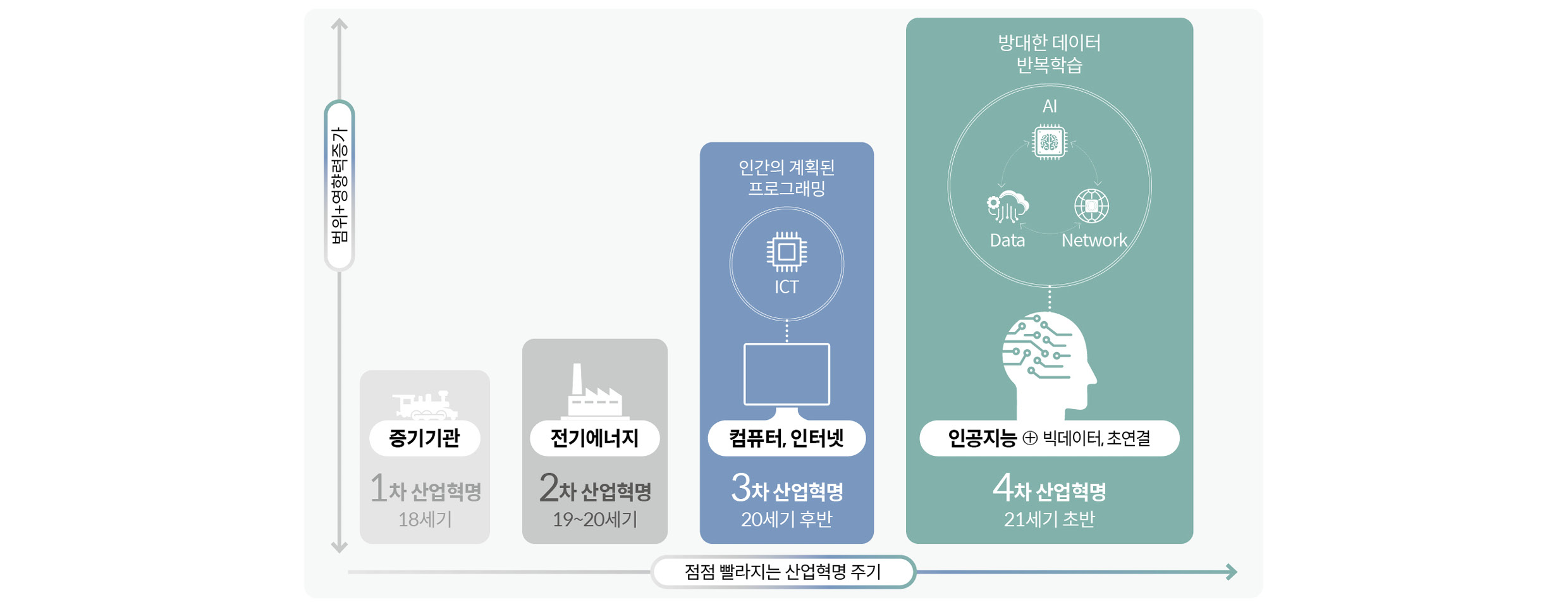
4차 산업혁명의 핵심이라 할 수 있는 AI 기술은 빠른 속도로 발전하고 있습니다. 오픈 소스, 라이브러리 기반의 개방된 개발 문화는 다양한 주체들이 서로의 경험, 정보, 지식을 공유하면서 새로운 지식을 빠르게 생산해내는 집단지성 효과를 불러일으키고 있죠. 데이터 수집을 비롯해 AI 모델의 학습, 평가, 관리 및 배포까지 하나의 파이프라인으로 구성해 제공하는 MLOps(Machine Learning Operations) 플랫폼 또한 AI 개발 속도를 높이는 도구 중 하나입니다.
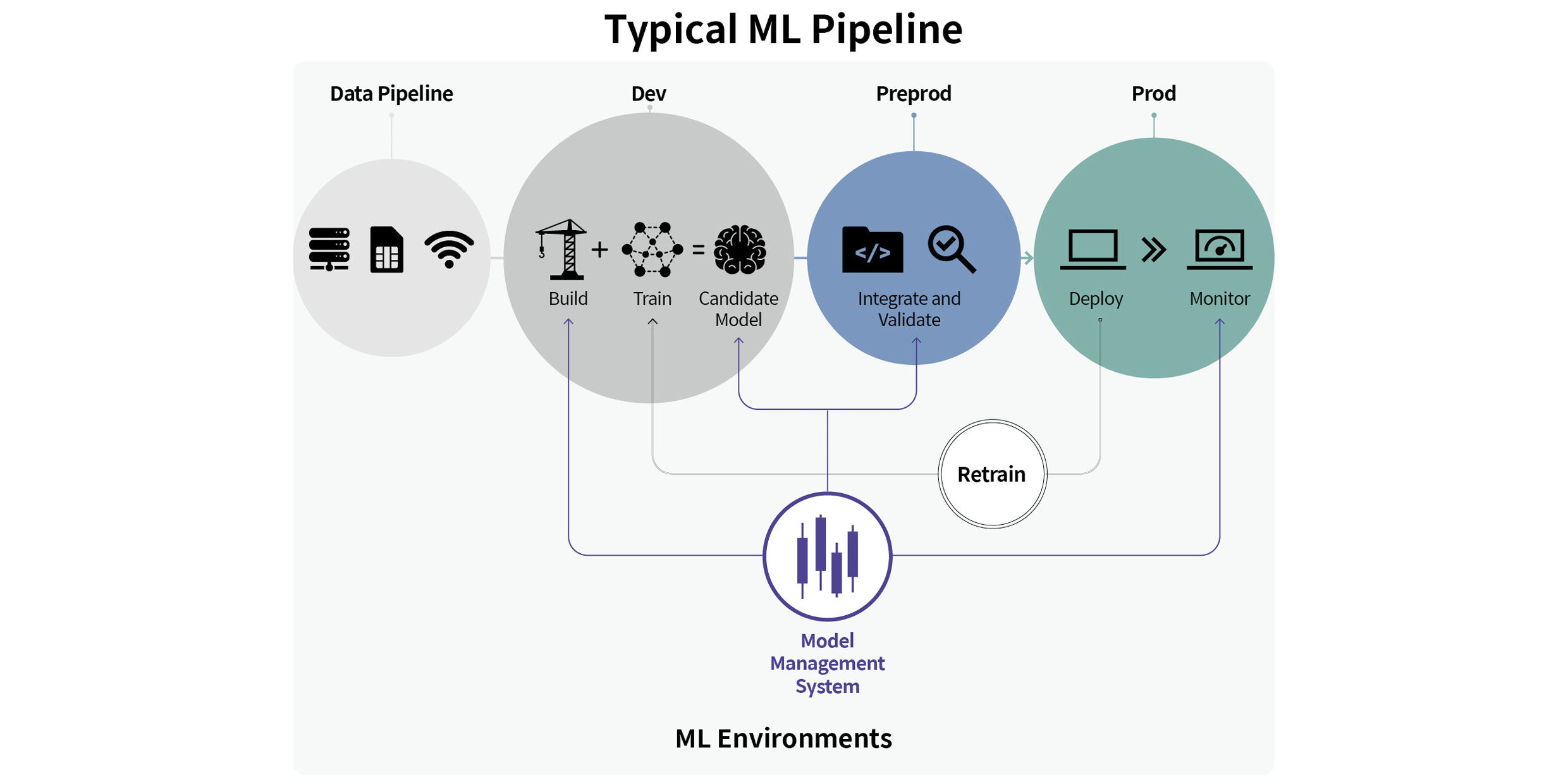
전문가는 소음과 진동 신호에 대한 전문 지식을 기반으로 특징 벡터를 추출하고 통계적 분포 및 특성에 따라 적합한 딥러닝 모델을 설계해 가장 우수한 상태 진단 성능을 도출합니다. 하지만 유사한 상태 진단 모델 학습 과정에서 반복되는 부분들이 존재하는 것을 발견했습니다. 저희는 소음, 진동 데이터를 이용해 차량의 상태를 진단하는 프로젝트와 AutoML(Automated Machine Learning)의 일종인 ENAS(Efficient Neural Architecture Search) 관련 연구를 진행한 경험을 바탕으로 반복되는 부분을 자동화할 수 있다면 개발 업무에 소요되는 시간을 크게 단축할 수 있을 것이라고 생각했습니다. 이를 실현하기 위해 소음, 진동 데이터에서 활용할 수 있는 모든 옵션을 파악하고, 플랫폼화한 A²DS 개발을 추진했습니다.
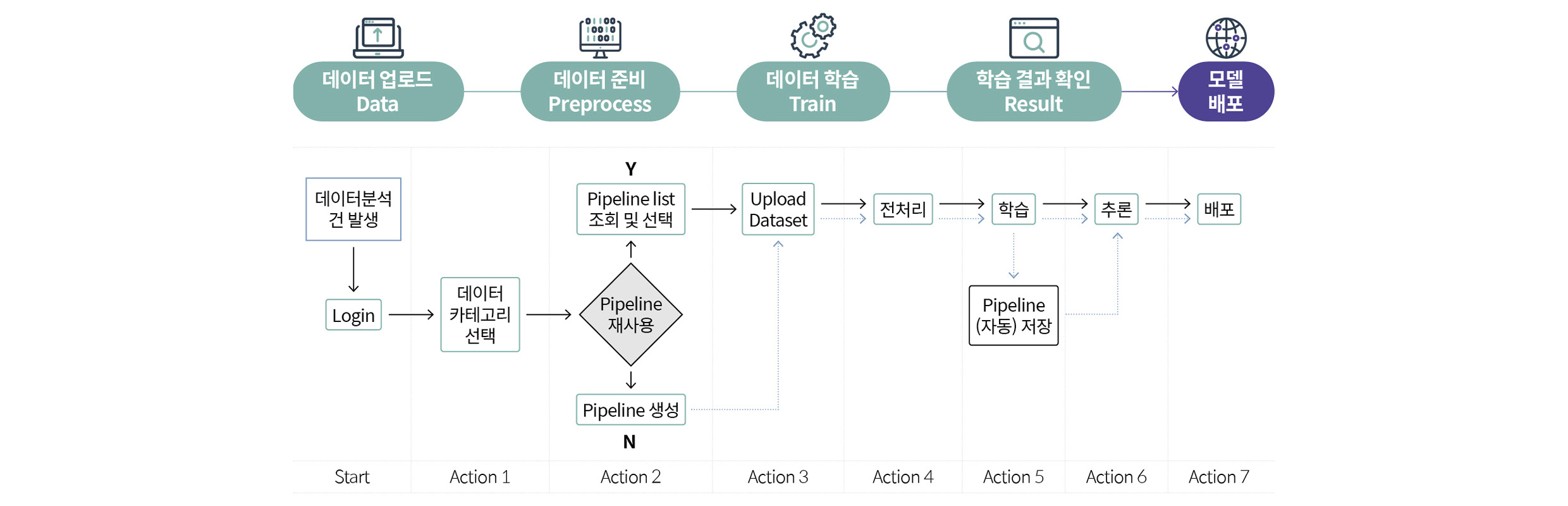
A²DS 개발에 앞서 두 가지 사항을 고려했습니다. 첫 번째는 ‘자동화’입니다. A²DS는 소음, 진동 신호의 전문 지식이 풍부한 AI 전문가를 비롯해 비전문가도 쉽게 사용할 수 있어야 했습니다. 이를 위해 모든 과정을 최대한 No code 형태로 구현해야 했죠. 아울러 가장 일반적으로 통용될 수 있는 파라미터(Parameter)들의 Default 값을 미리 설정해 개발자가 특별한 설정의 변경 없이 ‘Next’ 버튼만 누르면서 진행하더라도 최소 수준 이상의 결과를 보장할 수 있도록 했습니다. 뿐만 아니라 AI 전문가의 사용 편의성도 높일 수 있도록 전문가가 활용할 수 있는 다양한 옵션을 솔루션에 담아내려고 노력했습니다.
*No code : 프로그래밍 언어에 대한 지식이나 코딩 없이도 애플리케이션을 설계하거나 사용할 수 있도록 하는 접근방법 (cf. low code : 코딩을 없애지는 않지만 일반인도 쉽게 개발자와 유사한 코딩을 할 수 있도록 최소화, 간소화하는 것을 의미)
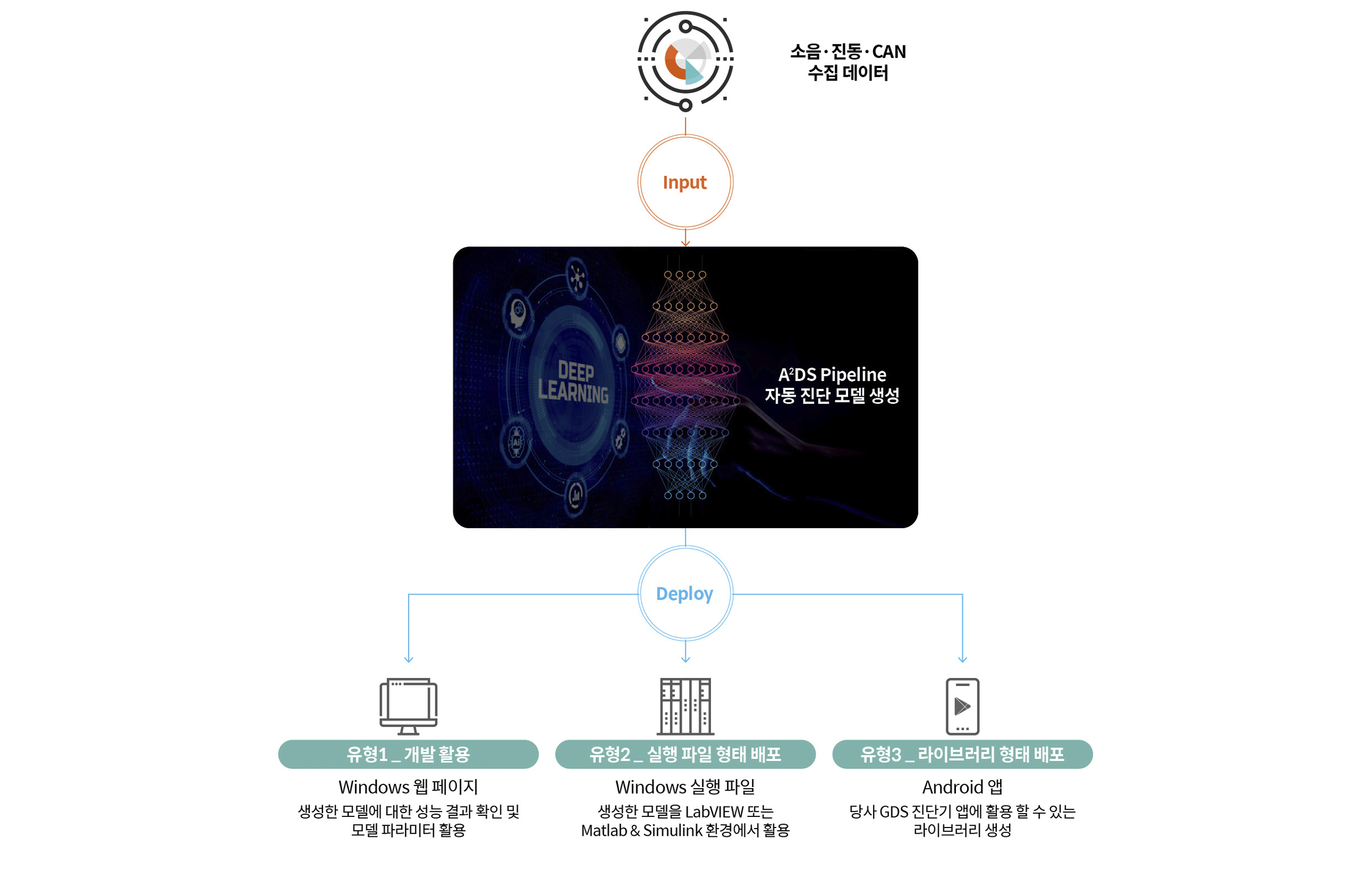
두 번째로 고려한 사항은 ‘배포 형태’입니다. 기본적으로 A²DS가 구동되는 웹 페이지 환경에서 AI 진단 모델의 성능 결과를 바로 확인하는 방법 외에도 실제 현장의 개발자들이 사용할 수 있는 배포 형태를 모두 담고자 했습니다. 현장에서는 윈도우 환경에서 LabVIEW 혹은 Matlab & Simulink을 활용해 개발하는 경우가 많았고, 안드로이드 태블릿 PC에 설치된 GDS(Global Diagnostic System) 장비에 탑재해 서비스에 사용하기도 했습니다. 따라서 윈도우 기반에서 동작할 수 있는 실행파일 형태와 안드로이드 애플리케이션 개발 시 사용 가능한 라이브러리 형태의 배포 방법을 추가로 구현했습니다.
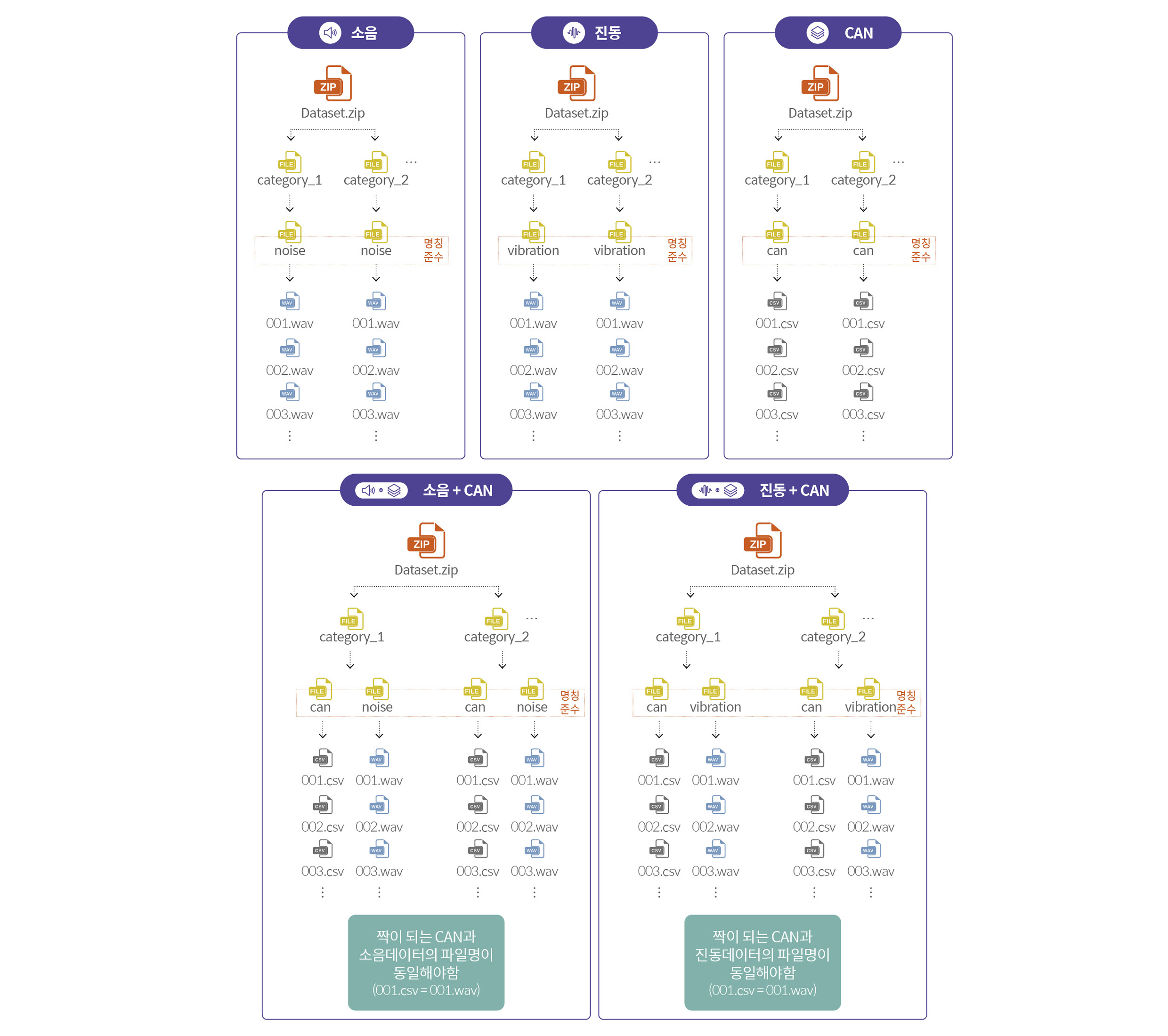
A²DS의 입력 데이터 유형은 현업에서 확인 가능한 소음, 진동, CAN(Controller Area Network) 데이터, 소음+CAN 데이터, 진동+CAN 데이터 등 총 5가지로 정의했습니다.

하지만 입력 데이터 유형을 정의한 후 개발자가 입력한 데이터 값을 A²DS가 어떻게 자동으로 구분해 읽어올 수 있는지에 대한 고민이 있었습니다. 자동화를 위해서는 데이터가 항상 동일한 규칙에 의해 정형화된 형식으로 입력되어야 하는데, 시스템에 입력될 수 있는 데이터는 소음, 진동, CAN 데이터가 다양한 조합으로 혼재되어 있기 때문이죠. 고민을 해결하기 위해 사용자에게 매뉴얼을 제공해 입력 데이터의 구성 규칙에 맞춰 데이터를 준비할 수 있도록 했습니다. 먼저 폴더 구조와 파일명 규칙을 정했습니다. 상태 진단을 위한 목표 클래스별로 폴더를 만들고, 폴더 내에서 소음, 진동, CAN 데이터별로 폴더를 생성하는 방식입니다.
아울러 짝이 되는 데이터끼리는 확장자를 제외한 파일명을 동일하게 입력하도록 했습니다. 소음, 진동 데이터가 ‘.wav’로 입력될 경우에는 헤더 정보가 존재하기 때문에 문제가 적습니다. 하지만 대부분 현장에서 발생하는 데이터가 ‘.csv’와 같은 텍스트이기 때문에 텍스트 데이터의 쓰기 방식에도 규칙이 필요했습니다. 첫 번째 열은 Time, 두 번째 열부터 N 번째 열까지는 하나의 채널 또는 CAN 데이터의 종류로 쓰며, 각 열의 구분은 콤마로 하는 규칙을 정했습니다.
다음으로 데이터 전처리 및 특징 벡터 추출 방법에 대해 설명 드리겠습니다. 그동안 쌓아온 개발 경험에 따르면, 잘 정제된 양질의 데이터를 보유하고 있는 양이 많은 경우에는 진단 모델의 데이터 전처리 및 특징 벡터 추출 방법에 대한 의존성이 줄어듭니다. 다시 말해, 데이터 전처리 및 특징 벡터 추출 방법을 전혀 사용하지 않거나 어느 정도만 선택하더라도 준수한 성능을 확보할 수 있다는 뜻입니다. 그러나 현장에서는 잘 정제된 양질의 데이터를 확보하기 쉽지 않으며, 비전문가가 수많은 입력 데이터에 가장 적합한 데이터 전처리 및 특징 벡터 추출 방법을 선택하기는 매우 어렵습니다.
비전문가도 쉽게 사용할 수 있도록 하기 위해 소음, 진동, CAN 데이터 유형 별로 가장 많이 쓰이는 몇 가지 전처리 방법과 특징 벡터 추출 방법을 구현해 Default 방법과 파라미터들을 설정했습니다. 내용을 잘 모르는 담당자의 경우 ‘Next’ 버튼을 누르는 것만으로 진단 모델을 만들 수 있도록 자동화해 사용 편의성을 높였습니다.
반면에 담당자가 전문가일 경우에도 원하는 방식으로 활용할 수 있도록 고려했습니다. 저희가 사용해봤던 다양한 소음, 진동, CAN 데이터에 관련된 전처리 방법들과 특징 벡터 추출 방법들을 최대한 구현해 옵션으로 제공할 수 있도록 고려했습니다. Default 방법과 파라미터들이 아닌 다른 옵션들을 시도할 경우, 기본적인 데이터 조작 및 전처리(입력 채널 선택, Crop, Resampling, Filtering 등), 시간 도메인 분석 기법(Zero Crossing Rate 등), 주파수 도메인 분석 기법(STFT, Mel-Spectrogram 등), 통계적 분석 기법(Root Mean Square, Variance 등), 음질 지수(Loudness, Sharpness 등), 차원 축소 등을 포함한 수십 가지의 방법과 관련 파라미터까지 개별적으로 선택하고 설정할 수 있도록 했습니다.
AI 모델 설계 자동화에 대해서도 설명해 보겠습니다. 이동철 책임의 모델 구조 자동화 기법 개발기 1탄에서 언급된 것처럼 저희 리서치랩은 AutoML 방법의 일종인 ENAS 기반의 진단 모델을 연구하였습니다. 하지만 이를 A²DS에 바로 적용하기는 쉽지 않았습니다. 우선 GPU 자원 등과 같은 인프라 제약이 있었고, 많은 학습 시간 또한 필요했습니다. 아울러 데이터가 적은 경우에는 학습이 원활하지 않거나 Overfitting이 쉽게 발생하는 현상이 일어나기도 했죠. 따라서 다른 두 가지 방법을 추가로 고려했습니다. 유튜브 오디오 데이터 기반의 대용량 데이터셋(Google AudioSet)을 사전 학습시킨 모델 PANN(Pre-trained Audio Neural Network)을 활용해 Transfer Learning을 통한 진단 모델을 학습하는 방법과 여러 가지 간단한 모델을 앙상블(Ensemble)해 사용하는 방법이었습니다.
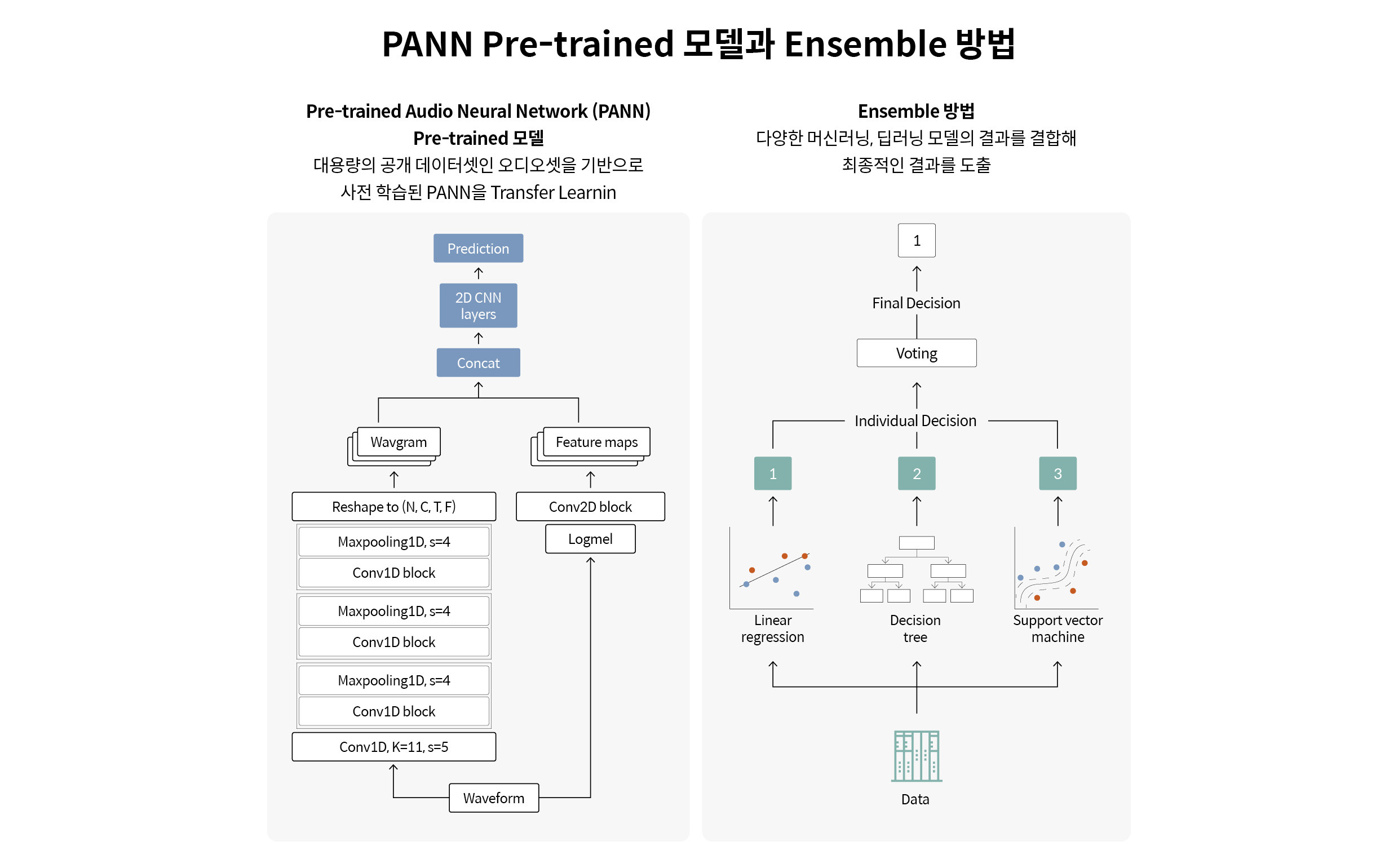
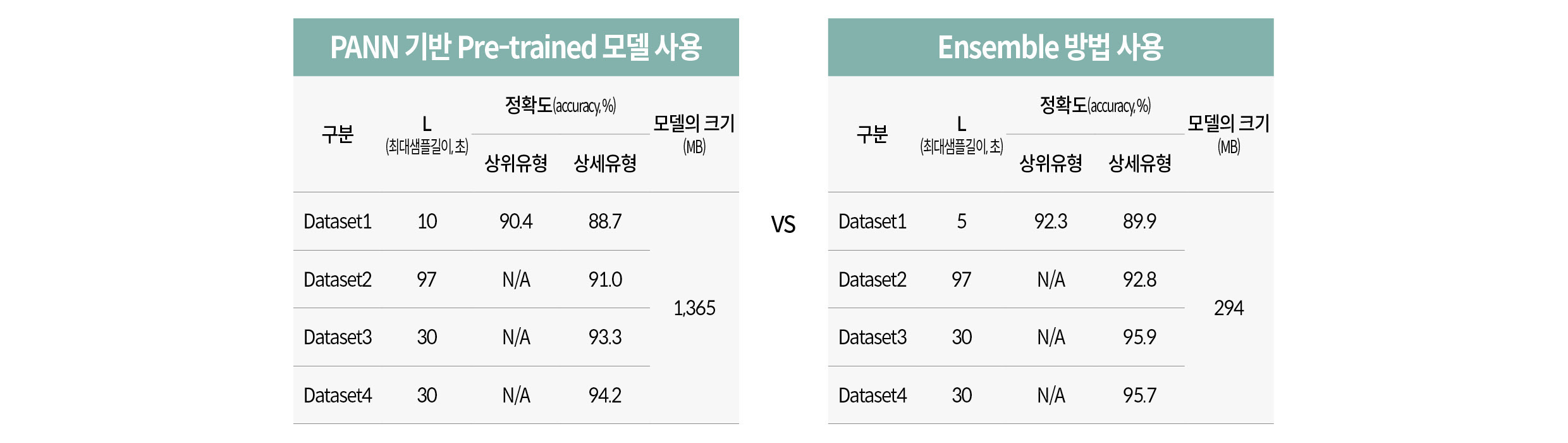
앙상블 모델은 여러 가지의 머신러닝, 딥러닝 모델이 각각 입력 데이터 유형별로 선택 가능한 특징 벡터로 각각 학습한 후 Weighted Majority Voting 방식으로 결합됩니다. 이때 성능을 더 높이기 위해 목표 성능을 설정하고 도달한 모델은 Early Stop 시키고, 목표 성능에 도달하지 못한 모델은 추가 학습을 진행해 취사선택하는 방식을 사용했습니다. 실험 결과, 리서치랩에서 보유한 4가지 종류의 소음, 진동, CAN 데이터셋에서 앙상블 모델이 PANN 기반의 Transfer Learning 방법 대비 모두 우수한 성능을 보였습니다. 또한 모델의 크기도 약 1/4 이상 작았습니다. 따라서 최종적으로 앙상블 모델을 A²DS에 채택했습니다.
AI 모델 학습 단계에서 개발자는 보유한 데이터셋을 학습, 검증, 평가 목적으로 원하는 비율에 맞춰 분할해 사용할 수 있고, 앞서 선택한 특징 벡터 추출 방법과 결합 가능한 머신러닝, 딥러닝 모델들을 선택해 앙상블 할 수 있습니다.
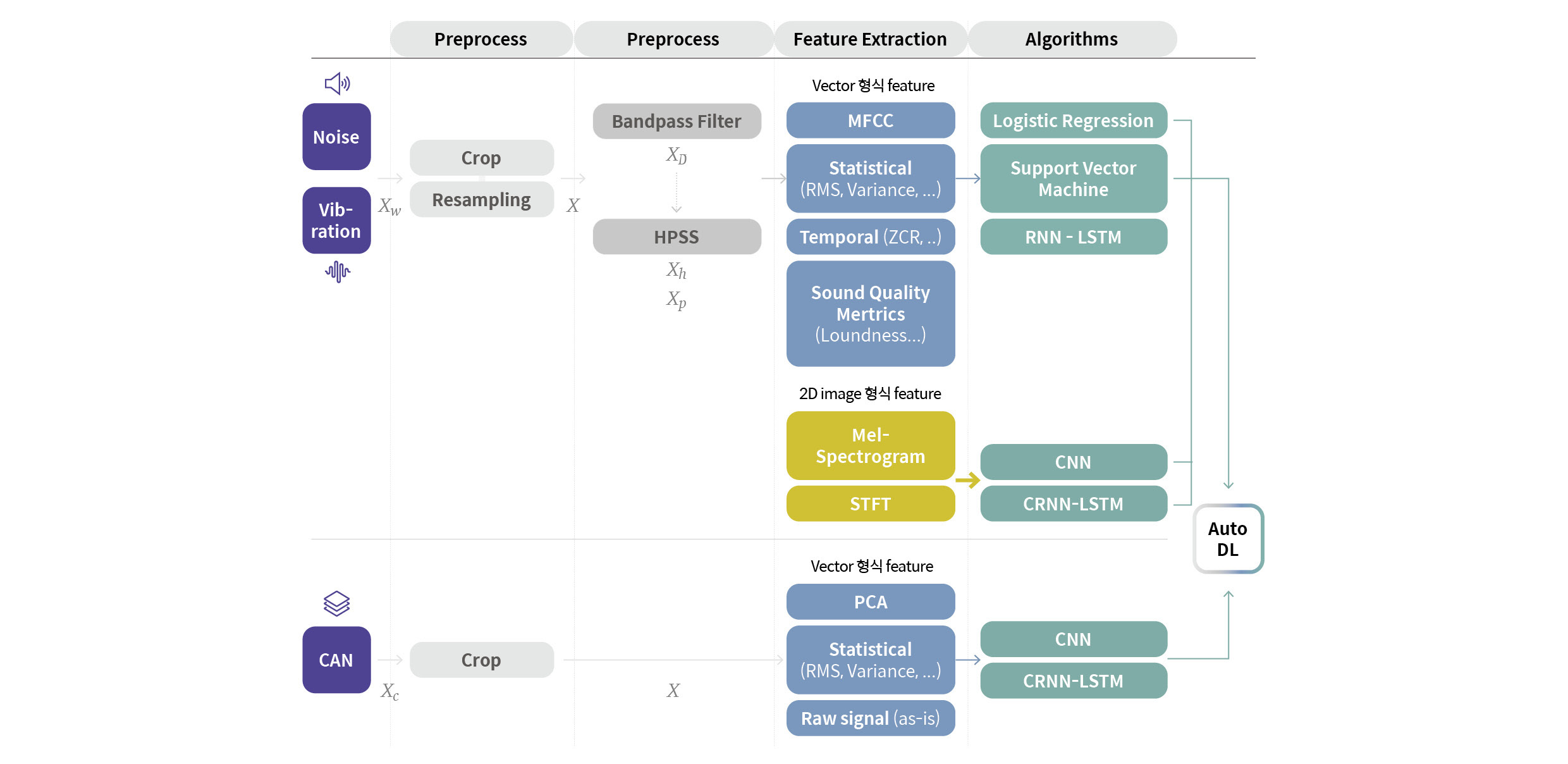
위 그림은 지금까지 설명한 데이터 업로드부터 AI 모델 학습까지의 단계를 요약한 것입니다. 각 입력 데이터 유형별로 적용 가능한 전처리 방법과 특징 벡터 추출 방법, AI 모델이 정리되어 있습니다.
소음, 진동 데이터는 Crop, Resampling, 주파수 필터와 HPSS(Harmonic Percussive Source Separation)로 전처리를 적용 가능하며, 특징 벡터 추출 방법의 Default 값으로는 MFCC와 Mel-Spectrogram이 선택되어 있습니다. 물론 필요시 다른 방법들을 추가로 선택할 수도 있습니다.
AI 모델은 특징 벡터의 차원에 따라 Logistic regression, SVM(Support Vector Machine), LSTM(Long-Shot Term Memory), CNN(Convolutional Neural Network), CRNN(Convolutional Recurrent Neural Network) 등을 선택할 수 있도록 구현했습니다.
CAN 데이터의 경우에는 전처리로 Crop 기능만 적용 가능하며, 특징 벡터 추출 방법은 PCA(Principle Component Analysis)가 Default 값으로 설정되어 있습니다. 마찬가지로 다른 특징 벡터를 추가하거나 Raw Signal 자체의 입력도 가능합니다.
AI 모델은 LSTM과 XGBoost(Extreme Gradient Boosting)를 사용할 수 있습니다. 종류가 다양한 CAN 데이터는 어떤 유형의 데이터가 입력될지 확신하기 어렵기 때문에 알고리즘의 선택 옵션을 소음, 진동 대비 다소 제한적으로 구성했습니다. 소음+CAN 데이터와 진동+CAN 데이터의 경우는 각각의 과정이 독립적으로 실행된 후 마지막 출력 단계에서 결과를 통합합니다.
이 단계를 모두 거치면 다음 화면에서 AI 모델 학습이 진행되며, 기록되는 Log와 Epoch 별 Loss, Accuracy, Confusion Matrix 등을 실시간으로 확인할 수 있도록 기능을 제공합니다.
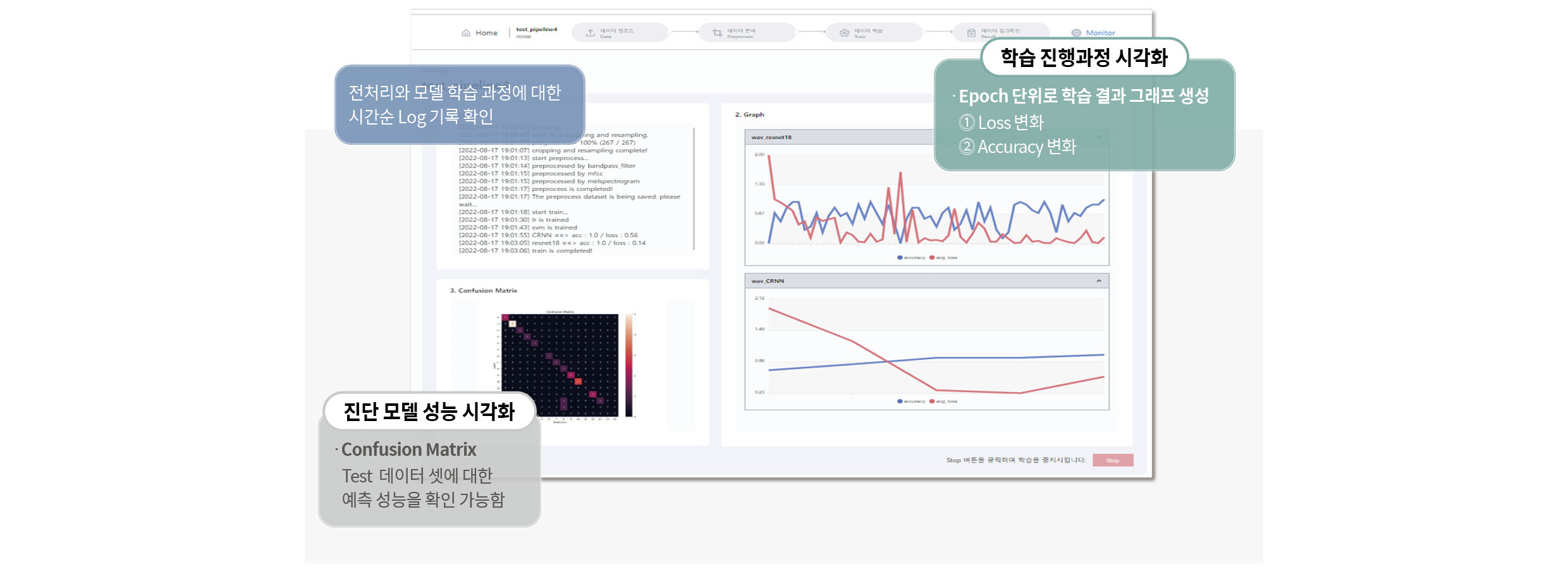

AI 모델 학습이 종료되면 입력 데이터에 대한 요약과 모델 성능 등을 다시 한번 확인하는 과정을 거치고, 마지막 단계인 배포 형태를 선택하는 과정에 돌입합니다.
배포 형태는 웹 페이지 환경에서 확인할 수 있는 형태, 윈도우 환경에서 LabVIEW 혹은 Matlab & Simulink에 기반하여 개발 시 사용 가능한 실행 파일 형태, 안드로이드 태블릿의 ‘.so’ 라이브러리 형태 등 총 3가지 중 하나를 선택할 수 있습니다. 웹 페이지 환경의 배포는 크게 고려할 사항이 없었으나 윈도우 실행 파일이나 안드로이드 애플리케이션용 라이브러리 형태로 배포하는 경우 저희가 만든 모델을 함수 형태로 다른 코드 안에 제공해야 하기 때문에 입출력의 형식을 정형화해야 했습니다. 그동안의 노하우를 반영하여 실행 파일 및 라이브러리에서 소음, 진동, CAN 신호 등이 파일로 저장되어 위치하는 경로값을 받고, 결과값은 각 클래스별 확률값을 텍스트로 출력하도록 구현했습니다.
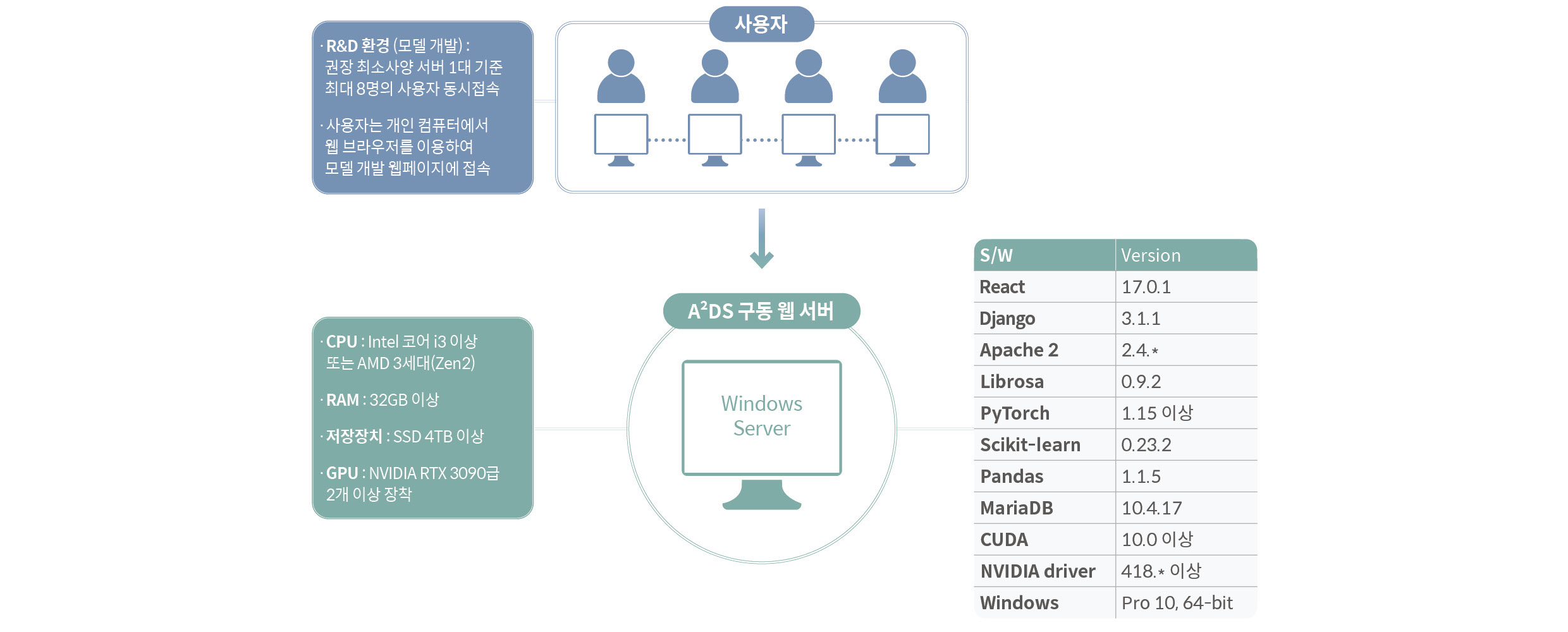
A²DS는 NVDIA RTX 3090급 이상의 고성능 GPU가 2개 이상 장착된 윈도우 서버에 설치하는 것을 권장합니다. 최대 8명의 사용자가 동시 사용 가능하며, 기타 하드웨어 권장 사항 및 설치된 파이썬 라이브러리의 버전에 대해서는 위 그림을 참고하시면 됩니다.
AI 자동 진단 솔루션 A²DS는 소음, 진동 신호 및 AI 분야의 비전문가와 전문가를 모두 타겟으로 합니다. 모든 과정은 No Code 형태이며, 복잡한 내용에 대한 이해나 설명 없이도 ‘Next’ 버튼만 눌러 자동으로 진단 모델을 생성할 수 있도록 개발했습니다. 아울러 AI 전문가도 필요한 옵션을 선택하고 파라미터를 변경해 사용 가능하도록 구현했습니다.
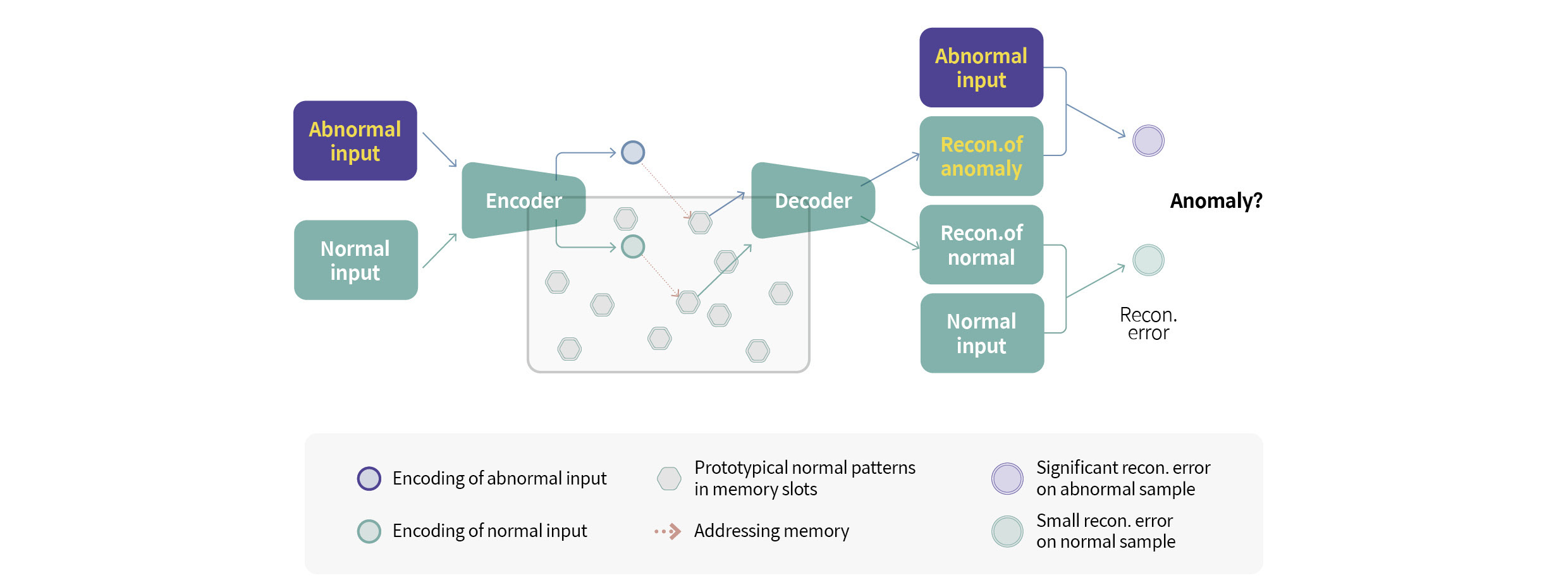
현재 A²DS는 AI 진단 모델에서 가장 일반적인 케이스 분류 모델로 정상과 비정상 데이터를 클래스별로 모두 수집하고 학습시키는 방법으로만 사용할 수 있습니다. 하지만 현장에서는 비정상 데이터를 수집하기 어려운 경우도 많습니다. 이와 같은 상황을 해결하기 위해 향후 A²DS에 이상 감지 모델(Anomaly detection)과 관련된 기능 추가를 준비하고 있습니다. 현대차그룹과 전동화음향진동리서치랩, 그리고 A²DS에 앞으로도 많은 관심 부탁드립니다.


